들어가며
정수론과 관련된 가장 기초적인 알고리즘부터, 응용 알고리즘까지 하나 하나 공부해 보고, 그 과정을 기록하려고 합니다.
소수
소수(Prime Number)는 정수론의 가장 중요한 연구 대상 중 하나로, 양의 약수가 1과 자기 자신 두 개 뿐인 자연수를 의미합니다. 소수의 반대되는 말은 세 개 이상의 양의 약수를 갖는 자연수를 합성수(Composite Number)라고 부릅니다.
예를 들어, 7은 1과 7 외에는 약수가 없기 때문에 소수입니다.
반면 9는 3으로 나누어 떨어지기 때문에 1, 3, 9가 9의 약수가 되고, 합성수입니다.
중요한 것은, 1은 소수도 아니고 합성수도 아닙니다. 꼭 기억합시다!
1. 가장 간단한 소수 판별 알고리즘
어떤 주어진 수가 소수인지 아닌지 판별하는 소수 판별 문제는 소수와 관련된 가장 기초적인 문제입니다.
이 문제를 효율적으로 해결하려는 많은 연구가 진행됐지만, 대부분의 효율적인 방법들은 너무 복잡해 실제 대회에서는 출제되지 않는다고 합니다. 그래서 저희는 가장 단순하면서 그나마 효과적인 방법을 사용합니다!
주어진 수 이 소수인지를 판단하는 가장 단순한 방법은 ~ 까지의 수 중 의 약수가 있는지 확인하는 것입니다. 만약 약수가 없다면 은 소수입니다.
#include <bits/stdc++.h>
using namespace std;
using ull = unsigned long long;
bool is_prime(ull n) {
if (n <= 1) return false;
if (n <= 3) return true;
if (n % 2 == 0) return false;
for (ull i = 2; i <= n - 1; i++) {
if (n % i == 0) return false;
}
return true;
}위 코드의 시간 복잡도는 부터 까지 한 번씩 확인하므로 이 됩니다.
최적화
앞서 설명한 알고리즘은 부터 까지 확인했습니다. 하지만, 아주 간단한 증명을 통해 까지가 아니라 까지만 확인하더라도 소수인지 아닌지 판별이 가능하다는 걸 아실 겁니다.
이 만약 합성수라면, 아래와 같이 두 자연수 로 나타낼 수 있습니다. (단, )
위 식을 약간 변형해 아래와 같은 부등식을 유도할 수 있습니다.
따라서 의 최솟값이자 의 최댓값은 이 되므로, 까지만 약수 검증을 하면 이 소수인지 아닌지 확인할 수 있게 되는 겁니다. 아래는 이를 구현한 예시 코드입니다.
#include <bits/stdc++.h>
using namespace std;
using ull = unsigned long long;
bool is_prime(ull n) {
if (n <= 1) return false;
if (n <= 3) return true;
if (n % 2 == 0) return false;
for (int i = 2; i <= sqrt(n); i++) {
if (n % i == 0) return false;
}
return true;
}위 코드의 시간 복잡도는 이 됩니다.
2. 에라토스테네스의 체
사실 위에서 설명한 알고리즘은 시간 복잡도에서의 효율이 좋지 못해 실제 PS에서는 많이 사용되지 않습니다. 지금 설명할 에라토스테네스의 체 알고리즘은 소수 및 소수의 개수를 구하는 방법에서 가장 보편적으로 사용되는 알고리즘으로 알려져 있습니다.
이 알고리즘의 기본 동작 방식은 소수의 배수들은 모두 합성수라는 성질을 이용해, 체로 걸러내듯 합성수를 걸러냅니다. 따라서 이 방식은 어떤 특정한 수가 소수인지 판별하기에는 좋은 방법이 아닙니다. 이하의 소수가 몇 개 있는지, 또는 이하의 소수들을 모두 직접 구할 때 유용하게 쓰일 수 있습니다.
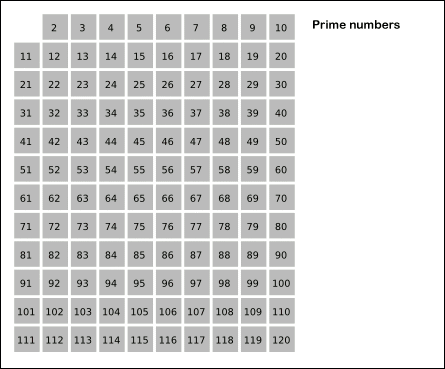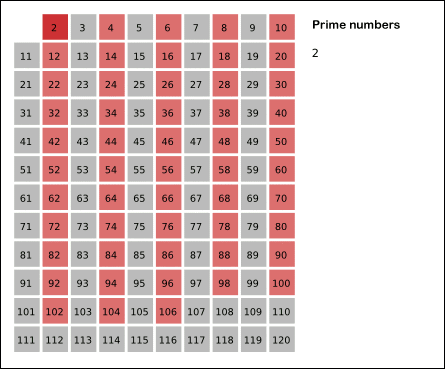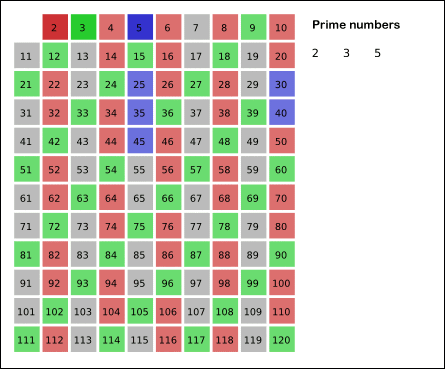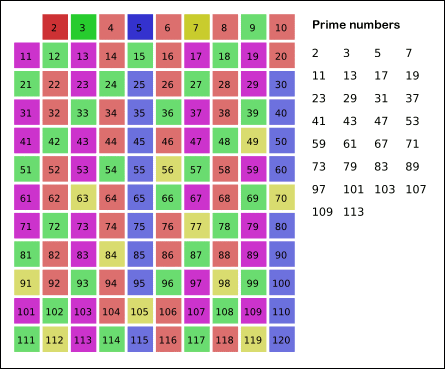
출처: 위키피디아
위 사진은 에라토스테네스의 체 알고리즘의 동작 방식의 이해를 돕기 위해 가져왔습니다. 실제로 아래에서 설명드릴 코드도 위와 같은 방식으로 동작합니다.
#include <bits/stdc++.h>
#define MAX_N 1000000
using namespace std;
using ull = unsigned long long;
int sieve[MAX_N + 1];
void eratos_init() {
for (int i = 2; i <= MAX_N; i++) {
if (!sieve[i]) {
for (int j = 2; j * i <= MAX_N; j++) sieve[i * j] = 1;
}
}
}에라토스테네스의 체 알고리즘의 시간 복잡도는 입니다. 이는 에 매우 근접한 시간 복잡도이며, 이 정도 까지는 수월하게 구할 수 있습니다.
3. 밀러-라빈 소수 판별법
어떤 수 이 소수인지 빠르게 판별하기 위해서는 앞서 설명한 에라토스테네스의 체 알고리즘이 적합하지 않을 수 있습니다. 그럴 때 사용할 수 있는 방법이 밀러-라빈 소수 판별법입니다.
밀러-라빈 소수 판별법은 어떤 특정한 수 이 소수인지 확률적으로 판단할 수 있는 알고리즘입니다. 여기서 말하는 확률적의 의미는, 밀러-라빈 소수 판별법을 적용했을 때, 이 합성수이거나 아마도 소수일 것이라고 판단을 해준다는 뜻입니다. 얼핏 보면 이 알고리즘의 정확도가 떨어질 수 있지만, 컴퓨터가 표현할 수 있는 자료형의 범위 내에서는 소수인지 정확히 판단이 가능하므로 이 알고리즘이 효율적으로 사용됩니다. (컴퓨터가 표현 가능한 자료형의 범위는 수학에서는 작은 수로 취급됩니다.)
밀러-라빈 소수 판별법을 이해하기 위해서는 정수론 지식이 필요합니다. 아래에서 설명할 두 가지의 보조 정리를 이해하고 있어야 이 알고리즘을 이해할 수 있습니다.
보조 정리 1 (페르마의 소정리)
- 가 소수이면, 모든 정수 에 대해
- 가 소수이고 가 의 배수가 아니면
보조 정리 2
소수 에 대해 이면,
(위 보조 정리가 성립하는 이유는 이 의 배수이므로, 또는 이 의 배수가 됩니다.)
위 두 보조 정리를 이해하셨다면, 아래에서 설명드릴 밀러-라빈 소수 판별법을 이해하실 수 있을 겁니다.
우선, 소수인지 아닌지 판별할 수 을 가 아닌 소수라고 가정합니다. 를 제외한 모든 소수는 짝수가 아니기 때문에, 은 짝수가 되고, 을 홀수가 될 때까지 로 나눠 준다면, 아래와 같이 표현할 수 있습니다.
여기서 는, 더이상 로 나눠지지 않는 홀수입니다.
그럼, 은 소수이기 때문에 양의 정수 에 대해 보조 정리 1 (페르마의 소정리)를 만족하게 됩니다. 즉, 아래의 식을 만족합니다.
위의 식은 또 다시 보조 정리 2를 만족하게 됩니다. 따라서 아래와 같습니다.
만약, 의 형태라면, 또 다시 보조 정리 2를 적용할 수 있고, 계속해서 이 나오는 경우 결국에는
가 됩니다. 위 식에서는 가 홀수이기 때문에 더 이상 보조 정리 2를 적용할 수 없게 되고, 우리는 위 과정을 통해 이 소수라면 보다 작은 양의 정수 에 대해 다음 둘 중 하나를 만족한다고 할 수 있습니다.
위 결과를 만족하면 왜 소수가 되는가?라는 의문이 생길 수 있는데, 위 식을 유도할 때 을 가 아닌 소수라고 가정하고 나온 결과라는 것을 생각한다면 쉽게 이해가 되실 겁니다.
그럼 위의 공식을 코드로 구현하여, 보다 작은 양의 정수 에 대해 만족하는지 테스트만 해 보면 이 소수인지 아닌지 판별이 가능합니다. 위대하신 공학자분들이 컴퓨터의 자료형 범위에서는 다음과 같은 에 대해서만 테스트를 해 봐도 이 소수라고 할 수 있다고 알려져 있기 때문에, 자료형에 따라 아래의 에 대해서만 테스트해 보면 됩니다.
- 형 범위 (비트 자료형) :
- 형 범위 (비트 자료형) :
만약 이 합성수라면, 보조 정리 1과 보조 정리 2를 만족하지 못하므로 테스트 과정에서 또는 이외의 다른 값이 나머지로 나올 것입니다.
아래는 위에서 설명한 로직을 C++로 구현한 예시 코드입니다.
#include <bits/stdc++.h>
using namespace std;
using ull = unsigned long long;
ull pow_dnc(ull a, ull n, ull MOD) {
if (n == 0) return 1 % MOD;
ull u = pow_dnc(a, n / 2, MOD);
u = (u * u) % MOD;
if (n % 2 == 1) u = (u * a) % MOD;
return u;
}
bool miller_rabin(ull n, ull a) {
if (a % n == 0) return false;
ull k = n - 1;
while (1) {
ull t = pow_dnc(a, k, n);
if (t == n - 1) return true;
if (k % 2) return (t == 1 || t == n - 1);
k /= 2;
}
}
bool is_prime(ull n) {
ull a[3] = { 2, 7, 61 };
//ull a[11] = { 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31 };
if (n <= 1) return false;
if (n <= 3) return true;
if (n % 2 == 0) return false;
for (int i = 0; i < 3; i++) {
if (n == a[i]) return true;
if (!miller_rabin(n, a[i])) return false;
}
return true;
}밀러-라빈 소수 판별법의 시간 복잡도는 입니다. 여기서 는 의 개수입니다. 이 때, FFT를 활용해 곱셈의 횟수를 줄인다면 시간 복잡도를 까지 줄일 수 있습니다. (고속 푸리에 변환은 잘 몰라서 공부하고 글을 작성하는 걸로...)