

기획 의도
‘가짜뉴스’의 위험성
- 고려대학교 정세훈 교수는 가짜뉴스가 과거로부터 계속 존재해왔던 현상이며, 풍자·루머·오보 등 여러 유사 개념과 혼용되어 사용되었다고 관훈 저널에서 발표했습니다. 사실과 다른 정보를 전달하는 내용적 측면, 실제 뉴스와 유사한 구조와 양식으로 기만하는 형식적 측면으로 구분했습니다. 이러한 가짜뉴스의 대응책으로 법적 규제, 자율 규제, 사실 확인, 미디어 리터러시 교육을 소개하고 있습니다.
- 이와 같은 논문이 발표될 만큼, 가짜뉴스의 영향력은 지속해서 향상하고 있습니다. 현대 사회에서 가짜뉴스는 개인 및 사회를 대상으로 명예 훼손, 마녀사냥, 허위 정보 유포 등 다양한 측면에서 심각성이 대두되고 있습니다. 나아가, 허위 정보로 인한 개인의 안전에 피해를 미치는 사례도 발견됩니다.
정확한 정보 보급 필요성 확인
- 2012년 제12회 인터넷 & 정보보호 세미나에서 정보의 홍수와 단편적 정보 속에서 생성된 맥락의 붕괴, 판단력 상실, 루머와 같은 불확실한 정보는 빠른 소셜미디어의 네트워크 확산 속도를 바탕으로 평균 4명을 거치면 대부분 연결된다고 발표했습니다. 이처럼, 오래전부터 인터넷의 장점 중 하나인 정보의 바다의 이면을 파악할 수 있습니다.
정확한 정보 제공 플랫폼 구축
- 프로젝트를 통해 뉴스를 포함한 각종 배포 정보의 사실성을 판정해주는 심판자의 역할뿐만 아니라 사실 검증을 위해 더 많은 데이터를 활용하여 중립성을 확보한 윤리적인 의무를 진 플랫폼을 구현하려고 합니다.
개발 과정
뉴스 데이터 크롤링
구글, 네이버, SBS 등의 사이트에서 실시간 뉴스를 크롤링하는 모듈을 제작했습니다. 또한 제작한 모듈을 활용해 딥러닝 모델의 학습 데이터를 구축했습니다.
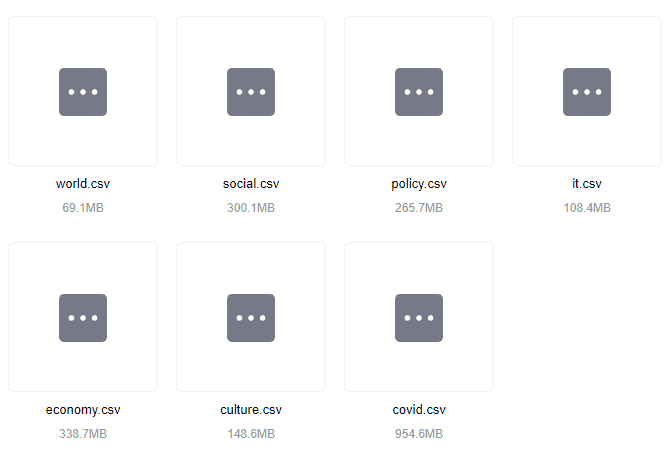
실시간 뉴스 데이터를 약 2 ~ 3일간 수집했습니다. 그 결과, 위와 같이 총 7개의 카테고리로 분류가 가능했고, 약 2GB의 학습 데이터를 수집할 수 있었습니다.
LSTM 모델 제작 및 학습
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, LSTM, Dropout, GlobalMaxPool1D
# 중략...
model = Sequential()
model.add(Embedding(max_word, 64, input_length=max_len))
model.add(LSTM(60, return_sequences=True))
model.add(GlobalMaxPool1D())
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(nb_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 중략...자연어로 구성된 글을 분류하는 데에는 여러가지 방법이 있습니다. Word2Vec, CNN, RNN 등등...
이 프로젝트에서 사용할 모델은 RNN의 종류 중 하나인 LSTM을 활용하여 위와 같이 구현했습니다. 분류할 클래스 수는 뉴스의 카테고리 수로 지정했습니다.
학습 데이터는 앞선 크롤링으로 수집한 뉴스 데이터를 통해 학습했습니다.
프로젝트 결과

위 사진에서 볼 수 있듯이, 특정 주제에 대한 뉴스의 신뢰성 검증은 잘 되는 것을 확인할 수 있습니다.

하지만, 위의 사진처럼 그 이외의 주제에 대한 신뢰성 검증은 잘 이루어지지 않는 것을 보실 수 있습니다.
이는 모델의 성능을 개선시킬 필요성이 있다고 생각하여, 추후 보완 사항으로 보완할 예정입니다.