들어가며
이전 포스팅에서는 소수 판별 알고리즘에 대해 알아봤습니다. 이번에는 어떤 수를 소인수분해하는 알고리즘들에 대해 알아 봅시다.
1. 가장 간단한 소인수분해 알고리즘
소수 판별 문제에서와 같이 가장 간단한 방법은, 소인수분해를 하려는 수 을 부터 까지 모두 나눠보는 겁니다. 만약 나눠진다면 해당 수는 의 인수가 됩니다. 아래는 이를 구현한 예시 코드입니다.
#include <bits/stdc++.h>
using namespace std;
using ull = unsigned long long;
vector<ull> prime_factor;
void prime_factorization(ull n) {
for (ull i = 2; i <= n; i++) {
while (n % i == 0) {
prime_factor.push_back(i);
n /= i;
}
}
}가장 간단하면서도, 가장 느린 알고리즘입니다. 시간 복잡도는 정도 되겠네요.
최적화
위의 코드를 조금만 수정해도, 시간 복잡도를 최적화할 수 있습니다.
어떤 수 을 소인수분해 했을 때, 나타날 수 있는 인수 중에서 가장 큰 값은 이라고 알려져 있습니다. 따라서 나눠보는 범위를 부터 까지로 줄인다면, 시간 복잡도는 이 됩니다. 아래는 예시 코드입니다.
#include <bits/stdc++.h>
using namespace std;
using ull = unsigned long long;
vector<ull> prime_factor;
void prime_factorization(ull n) {
for (ull i = 2; i * i <= n; i++) {
while (n % i == 0) {
prime_factor.push_back(i);
n /= i;
}
}
if (n > 1) prime_factor.push_back(n);
}2. 에라토스테네스의 체를 이용한 소인수분해
소수 판별 알고리즘에서 설명드린 에라토스테네스의 체를 이용하여 소인수분해를 할 수 있습니다.
이 알고리즘은 주어진 범위의 소수의 개수에 따라 시간 복잡도가 선형으로 증가합니다. 따라서, 앞서 설명드린 까지 직접 나눠보며 소인수를 구하는 방법과 비교했을 때, 소인수가 적은 수에 대해서는 두 방법의 속도 차이가 크지 않을 수 있지만, 소인수가 많은 수에 대해서는 에라토스테네스의 체를 이용한 소인수분해가 더 효율적일 것입니다.
하지만, 소인수분해 대상 수가 매우 큰 경우에는 두 방법 모두 성능이 좋지 않을 수 있습니다. 이런 경우에는 보다 효율적인 알고리즘을 사용해야 합니다.
아래는 에라토스테네스의 체를 이용하여 소인수분해하는 예시 코드입니다.
#include <bits/stdc++.h>
#define MAX_N 10000000
using namespace std;
using ull = unsigned long long;
int sieve[MAX_N + 1];
vector<ull> prime_factor;
void eratos_init() {
for (int i = 2; i <= MAX_N; i++) {
if (!sieve[i]) {
for (int j = 2; j * i <= MAX_N; j++) sieve[i * j] = 1;
}
}
}
void prime_factorization(ull n) {
for (int i = 2; n > 1; i++) {
if (!sieve[i]) {
while (n % i == 0) {
prime_factor.push_back(i);
n /= i;
}
}
}
}위 코드의 시간 복잡도는 으로 과 매우 근접한 시간 복잡도라고 알려져 있습니다.
3. 폴라드 로 알고리즘 (Pollard's Rho Algorithm)
폴라드 로 알고리즘은 소인수분해를 평균적으로 에 할 수 있는 상당히 빠른 알고리즘입니다. 엄밀한 정의는 소인수분해가 아닌, 몬테카를로적으로 진약수를 찾아주는 인수분해 알고리즘이지만, 이를 적당히 빠른 소수 판별 알고리즘과 함께 재귀적으로 소인수분해를 진행할 수 있어 PS에서 많이 쓰인다고 합니다.
하지만, 앞서 설명했듯이 폴라드 로 알고리즘은 평균적으로 의 시간 복잡도를 가집니다. 이는 언제나 의 시간이 보장되지는 않습니다. 그 이유는 이 알고리즘이 의사 난수를 활용해 휴리스틱하게 동작하기 때문입니다.
우선 폴라드 로 알고리즘을 이해하기 위해서는 생일 문제와 플로이드 순환 찾기 알고리즘을 알고 있어야 합니다. 해당 알고리즘의 핵심 아이디어이므로, 아래에서 간단히 설명해 드리겠습니다.
생일 문제 (비둘기 집의 원리)
만약, 366명의 사람들 중 생일이 같은 사람이 존재하는지 묻는 문제가 있다면, 이 문제의 정답은 예일 것입니다. 그 이유는 비둘기 집의 원리를 적용하면 쉽게 생각해낼 수 있습니다. 365명의 사람을 한 사람씩 1월 1일, 1월 2일, 1월 3일, ... 12월 31일에 배정하면, 마지막 366번째 사람은 어떤 날에 배정해도 누군가와는 생일이 같게 됩니다.
플로이드 순환 찾기 알고리즘
이 알고리즘은 정말 간단하게 이해하실 수 있습니다.
사이클이 없는 유향 그래프가 있다고 가정하고, 그 유향 그래프의 어떤 정점에서 토끼와 거북이가 같은 방향으로 출발한다고 생각해 봅시다. 이 때 토끼는 2칸씩, 거북이는 1칸씩 이동하면 매 스텝마다 토끼와 거북이는 1칸씩 멀어지게 됩니다.
하지만, 사이클이 존재하는 유향 그래프에서는 토끼와 거북이가 위와 같이 출발하더라도 토끼는 거북이의 뒤에 있는 것으로 볼 수 있고, 매 스탭마다 토끼와 거북이는 1칸씩 가까워지게 되므로, 언젠가는 토끼와 거북이가 만나게 됩니다.
동작 과정
비둘기 집의 원리와 플로이드 순환 찾기 알고리즘을 이해하셨다면, 아래의 폴라드 로 알고리즘의 동작 과정도 이해하실 수 있을 겁니다. 사실 몰라도 당연한 말들이라 이해하기엔 문제가 없을 겁니다...
우리는 소수가 아닌 이상의 자연수 을 인수분해하는 문제를 해결하려고 합니다.
그럼 우선, 아래와 같은 함수 를 정의합니다.
그리고 어떤 랜덤한 초기값 으로 시작하여 귀납적으로
를 구해나갑니다. (이 때, 는 의 인수입니다.). 이로 인해 임의의 수열 를 얻을 수 있고, 구한 수열은 비둘기 집의 원리에 의해 개 이하의 정점을 갖는 사이클을 형성하게 됩니다. 그 이유는 로 모듈러 연산을 하게 되면 그 값은 에 속하기 때문입니다.
즉, 그래프를 시각화하면 아래와 같은 모양의 사이클을 갖는 그래프가 될 것입니다.
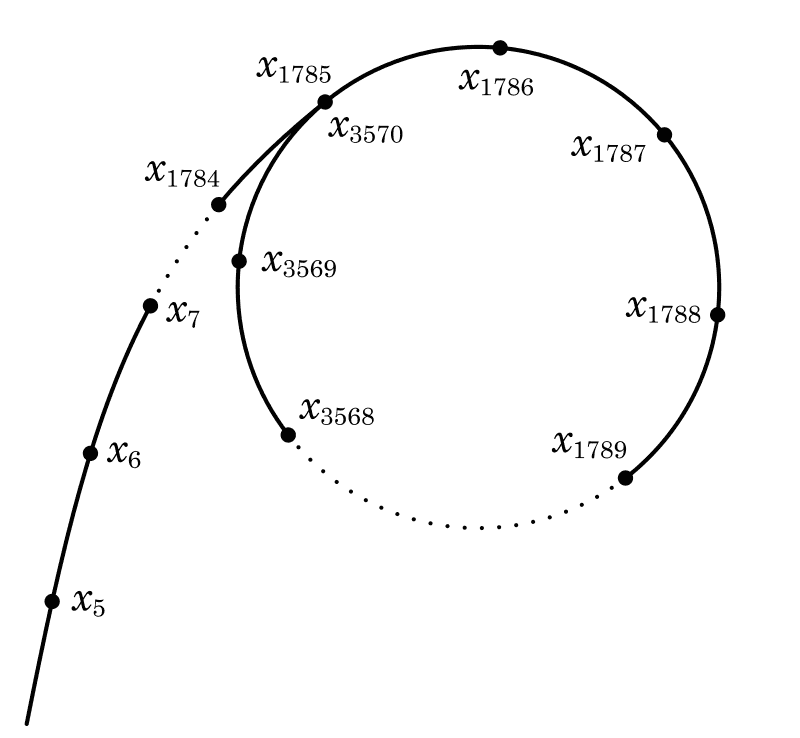
출처: 위키피디아
위와 같이 의 약수 에 대해서 수열이 사이클을 이룬다면, 어떤 항 와 에 대해 인 값이 존재할 것입니다. 조금 다르게 표현하면 가 성립하고, 와 모두 로 나누어 떨어지므로 을 구했을 때 보다 크고 이 아니면 그 값은 의 약수라고 할 수 있습니다.
사이클이 존재하는 수열을 탐색하는 방법은 플로이드 순환 찾기 알고리즘을 활용합니다.
수열의 초항인 와 를 사이의 랜덤한 값으로 설정하고, 는 한 칸씩, 는 두 칸씩 이동합니다. 만약 이동하다가 가 성립한다면, N의 약수를 구한 것이기 때문에 그 약수를 반환합니다.
하지만 수열을 탐색하다가 와 가 만난 경우, 즉 인 경우에는, 해당 수열을 다 탐색했음에도 약수 찾기에 실패한 것이므로 수열의 초항인 와 의 상수항 를 랜덤하게 바꿔 다시 위의 과정을 수행하면 됩니다.
마지막으로, 위에서 정의한 의 약수 와 의 상수항 를 설정해 주면 됩니다. 의 약수인 는 또한 의 약수이므로 으로 설정해 주면 되고, 상수항 또한 적당히 작은 랜덤한 값으로 설정해 주면 됩니다.
아래는 폴라드 로 알고리즘의 동작 과정을 구현한 코드입니다.
#include <bits/stdc++.h>
using namespace std;
using ull = unsigned long long;
using i128 = __int128;
i128 pow_dnc(i128 a, i128 n, i128 MOD) {
if (n == 0) return 1 % MOD;
i128 u = pow_dnc(a, n / 2, MOD);
u = (u * u) % MOD;
if (n % 2 == 1) u = (u * a) % MOD;
return u;
}
bool miller_rabin(i128 n, i128 a) {
if (a % n == 0) return false;
i128 k = n - 1;
while (1) {
ull t = pow_dnc(a % n, k, n);
if (t == n - 1) return true;
if (k % 2) return (t == 1 || t == n - 1);
k /= 2;
}
}
bool is_prime(i128 n) {
//ull a[3] = { 2, 7, 61 };
i128 a[12] = { 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37 };
if (n <= 1) return false;
if (n == 2 || n == 3) return true;
if (n % 2 == 0) return false;
for (int i = 0; i < 12; i++) {
if (n == a[i]) return true;
if (!miller_rabin(n, a[i])) return false;
}
return true;
}
ull pollard_rho(ull n) {
if (is_prime(n)) return n;
if (n == 1) return 1;
if (n % 2 == 0) return 2;
ull x, y, c, d = n;
x = y = rand() % (n - 2) + 2;
c = rand() % 20 + 1;
d = 1;
while (d == 1) {
x = ((((i128)x * (i128)x) % n) + c) % n;
y = ((((i128)y * (i128)y) % n) + c) % n;
y = ((((i128)y * (i128)y) % n) + c) % n;
d = gcd(max(x, y) - min(x, y), n);
if (d == n) return pollard_rho(n);
}
return pollard_rho(d);
}
int main() {
ull x = 25;
vector<ull> res;
while (x > 1) {
ull dv = pollard_rho(x);
res.push_back(dv);
x /= dv;
}
sort(res.begin(), res.end());
for (auto i : res) cout << i << '\n';
return 0;
}